All questions related to Real-Time Image Super-Resolution Challenge can be asked in this thread.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Real-Time Image Super-Resolution Challenge
- Thread starter Andrey Ignatov
- Start date
Or is there a minimum performance requirement or a maximum time limit?
No, there is no max time limit.
What is the basis for the final ranking?
What is the ratio of performance to running time?
The final submission score will be proportional to the findelity score (PSRN and SSIM) and inversely proportional to the runtime. The exact scoring formula will be announced a bit later.
Hello, I am confused the dimension of AI Benchmark input since the input shape is dynamic.
The input size of the TFLite model should be constant, so you don't need to use dynamic input shape. The size of the input will be equal to ~
360 x 640 px, we will send the exact instructions soon when we open the runtime validation submission.does the AI Benchmark support tf.space_to_depth layer?
Yes, space to depth layer is supported by CPU, GPU and NNAPI TFLite delegates (for both INT8 and FP16 inference). Looks like you have also changed something else.
deepernewbie
New member
It seems like Upsampling2D layer is not supported
It seems like Upsampling2D layer is not supported
Upsampling2D layer is supported, please follow this tutorial for more details (especially check the information about the experimental_new_converter flag). If the problem is still there - please start a new thread here.deepernewbie
New member
Thanks I have tried it with experimental_new_converter off and it works at least with my setup (samsung phone, ubuntu, tensorflow 2.3)Upsampling2Dlayer is supported, please follow this tutorial for more details (especially check the information about theexperimental_new_converterflag). If the problem is still there - please start a new thread here.
Hello, I have a few more questions about the runtime requirement.
Before testing phases, will there be a remote platform that can evaluate our model runtime on the target device?
Like it said in the organizer email, "on a recent smartphone CPU such model would be able to run in less than 0.2s for example." Is this "0.2s" ran on CPU with XNNPACK option on or not? This option seems to have a great impact on CPU runtime according to AI Benchmark.
Before testing phases, will there be a remote platform that can evaluate our model runtime on the target device?
Like it said in the organizer email, "on a recent smartphone CPU such model would be able to run in less than 0.2s for example." Is this "0.2s" ran on CPU with XNNPACK option on or not? This option seems to have a great impact on CPU runtime according to AI Benchmark.
it even takes half an hour for each picture.
I guess the problem was with Codalab, should be okay now.
will there be a remote platform that can evaluate our model runtime on the target device?
Everyone should include their TFLite models in the Codalab submission archive. The runtime results of the previously submitted models will be released today and will be updated regularly starting from now.
Is this "0.2s" ran on CPU with XNNPACK option on or not?
Yes, with XNNPACK. Please note that this value (0.2s) was provided only for the reference: if your solution is much slower when running it on CPU, then it is very likely that it won't be running fast or Synaptics NPU.
deepernewbie
New member
I believe the evaluation and tflite format should be cleared in more detail. First of all to process all of the validation images which are different in size the model should be trained with size (None,None,3) however in the recent mail it states that the input size should be (360,640,3). How can we process the div2k validation test set with this Input size (should we crop if so how if not how can we achieve consistency between processed images and tflite file with constant input size) - Personally what I did was Trained the model with (None,None,3) and added an additional Input layer with (360,640,3) to force ai-benchmark app to use that size while calculating the runtime, however I included my original tflite file which is used to process the images. I wish that part was clearer.
Regarding to 0.2s reference Even a single Upsampling2D(size=3,interpolation="bilinear") layer is running in ~250ms on my device (Samsung Galaxy A21s scores 6.8 in ai-benchmark) So that 0.2 is very much device dependent. So there should be another way of measure how performant out model can be. My suggestion is Please run a reference model like (FSRCNN) on the target platform and a couple of different mobile phones and share the run times with the reference tflite model. So we can get an idea where our device sits and plan accordingly (For ex: If the reference model which runs in 30ms in Synaptics SoC and 200ms in a device with ai-benchmark score 15 and 500ms in a device with ai-benchmark score 5 and my phone runs it in 400ms, I can say I should be around that and focus on models achieving that runtime score
Another issue is for a model the comment was Transpose operation is not supported on target platform I assume that It is the regular transpose operation not Conv2dTranspose
Last but not least, I can succesfully get a model only including conv2d and tf.nn.depth_to_space(x, scale) and can get a tflite file succesfuly however while running the model in the ai-benchmark app, app crashes I tried it with converter.experimental_new_converter = True/False it is the same. Here I attach the tflite file model_no_quant.tflite works model_quant.tflite fails with app crash
Regarding to 0.2s reference Even a single Upsampling2D(size=3,interpolation="bilinear") layer is running in ~250ms on my device (Samsung Galaxy A21s scores 6.8 in ai-benchmark) So that 0.2 is very much device dependent. So there should be another way of measure how performant out model can be. My suggestion is Please run a reference model like (FSRCNN) on the target platform and a couple of different mobile phones and share the run times with the reference tflite model. So we can get an idea where our device sits and plan accordingly (For ex: If the reference model which runs in 30ms in Synaptics SoC and 200ms in a device with ai-benchmark score 15 and 500ms in a device with ai-benchmark score 5 and my phone runs it in 400ms, I can say I should be around that and focus on models achieving that runtime score
Another issue is for a model the comment was Transpose operation is not supported on target platform I assume that It is the regular transpose operation not Conv2dTranspose
Last but not least, I can succesfully get a model only including conv2d and tf.nn.depth_to_space(x, scale) and can get a tflite file succesfuly however while running the model in the ai-benchmark app, app crashes I tried it with converter.experimental_new_converter = True/False it is the same. Here I attach the tflite file model_no_quant.tflite works model_quant.tflite fails with app crash
Attachments
Why is the input size required in tf lite (360x640), but the submitted result requires the original size?Traceback (most recent call last):
File "/tmp/codalab/tmpSCpd0D/run/program/evaluation.py", line 95, in
raise Exception('Expected %d .png images'%len(ref_pngs))
Exception: Expected 100 .png images
First of all to process all of the validation images which are different in size the model should be trained with size (None,None,3)
You should just export / convert your model twice: with constant input size (for runtime evaluation) and with dynamic input size (for image results generation).
So that 0.2 is very much device dependent. So there should be another way of measure how performant out model can be.
You can just train a simple model and submit it to Codalab for runtime evaluation on the target Synaptics platform. Later on, you can refer to the results obtained with this model.
Here I attach the tflite file model_no_quant.tflite works model_quant.tflite fails with app crash
Quantized
depth_to_space op works only with the latest nightly TFLite build. The corresponding AI Benchmark version will be published here on the 10th of March, the provided model runs fine with it. We are also trying to provide you with beta access to this build via the Google Play now.Why is the input size required in tf lite (360x640), but the submitted result requires the original size?
Please don't confuse model runtime and fidelity evaluation:
1. For evaluating model runtime, you need to get a TFLite model processing the images of resolution
360 x 640 pixels.2. To check the quality of the reconstructed visual results, your model should process the images of original size (actually, not original - downscaled by a factor of 3).
mrblue3325
New member
Hello
I used the standard code provided in github.
When I used the DIV2K test set to test the tflite model, some images do not meet the requirement of 360x640.
Is it ok for us to not test those images when we submit the sr images package?
I used the standard code provided in github.
When I used the DIV2K test set to test the tflite model, some images do not meet the requirement of 360x640.
Is it ok for us to not test those images when we submit the sr images package?
Hello
I got "Inference fails" in https://docs.google.com/spreadsheet...Qzziq8Ejy6w2_7qhP7Fmy5K5X4jfa9iZC5xpb/pubhtml. But it run sucessfully in AI Benchmark with Int8 and CPU option. And shape of input tensor is [1,360,640,3], shape of output tensor is [1,1080,1920,3]. Can you give me some advice? Thank you~
I got "Inference fails" in https://docs.google.com/spreadsheet...Qzziq8Ejy6w2_7qhP7Fmy5K5X4jfa9iZC5xpb/pubhtml. But it run sucessfully in AI Benchmark with Int8 and CPU option. And shape of input tensor is [1,360,640,3], shape of output tensor is [1,1080,1920,3]. Can you give me some advice? Thank you~
Is it ok for us to not test those images when we submit the sr images package?
Please check the above response. You need to submit all SR images images to Codalab.
Can you give me some advice?
I checked your model - it is very computationally expensive: its runtime is more than 2 seconds per frame with NNAPI on much more powerful mobile SoC, thus it won't be running fine on the Synaptics NPU. Try removing or replacing some layers / ops (e.g., Leaky Relu with Relu or TransposeConv with ResizeBilinear) to reduce its runtime on CPU / with NNAPI.
Last edited:
What is the version of tensorflow that supports quantize ‘depth to space‘?
You should install TensorFlow Nightly build (or tf-nightly-cpu for CPU only inference).
@deepernewbie, @Zhang9678,
The new AI Benchmark beta version was finally published in the Google Play. To download it, go to AI Benchmark page in the Google Play Store and select the Join the beta option. You will then get a notification that a new update is available. With the latest AI Benchmark build,
The new AI Benchmark beta version was finally published in the Google Play. To download it, go to AI Benchmark page in the Google Play Store and select the Join the beta option. You will then get a notification that a new update is available. With the latest AI Benchmark build,
depth_to_space op should be running fine.Which op is not optimized in your NPU accelerator?
Please check the last section in the Runtime Evaluation tab here.
How long would it take for the element-wise op (add) if the op not optimized?
You can submit your model with the corresponding ops to Codalab and get its runtime in this Google Doc.
--Tensorflow-gpu version: [2.2.0]
First of all, you need to install TensorFlow Nightly build (or at least TF 2.4) for model conversion, older TF versions don't have TFLite implementations for many ops.
Conversion: [tf.lite.TFLiteConverter.from_concrete_functions]
Please check carefully TFLite conversion instructions provided here.
Additionally, some quantized ops are supported only in the latest AI Benchmark beta build, you can follow this post to install it.
Hi,
I try to use quantization-aware training and failed. The error is "TypeError: tf__call() got an unexpected keyword argument 'block_size'".
I print the layer of my model and find that the depth_to_space layer has a parameter 'block_size'
Can you give me some advise? Thank you~
-- tf version: tf-nightly 2.5.0.dev20210310
I try to use quantization-aware training and failed. The error is "TypeError: tf__call() got an unexpected keyword argument 'block_size'".
I print the layer of my model and find that the depth_to_space layer has a parameter 'block_size'
It seems that "tf.nn.depth_to_space" layer cannot be used with quantization-aware training. The same thing happens with "tf.concat" layer.{'name': 'tf.nn.depth_to_space', 'inbound_nodes': [['conv2d', 0, 0, {'block_size': 3}]]}
Can you give me some advise? Thank you~
-- tf version: tf-nightly 2.5.0.dev20210310
deepernewbie
New member
Hi richlaji first of all great to see your challenging timing scores well done and good luck!Hi,
I try to use quantization-aware training and failed. The error is "TypeError: tf__call() got an unexpected keyword argument 'block_size'".
I print the layer of my model and find that the depth_to_space layer has a parameter 'block_size'
It seems that "tf.nn.depth_to_space" layer cannot be used with quantization-aware training. The same thing happens with "tf.concat" layer.
Can you give me some advise? Thank you~
-- tf version: tf-nightly 2.5.0.dev20210310
I can help you with that, try to wrap tf.nn.depth_to_space with Lambda layer since tf.nn is tensorflow operator, but Lambda encapsulates it as a keras layer. Same applies for "+" operator it is a tensorflow operator but Add()(...) is a keras layer so don't mix keras layers with tf operators.
Best.
Thank you for your sharing~Hi richlaji first of all great to see your challenging timing scores well done and good luck!
I can help you with that, try to wrap tf.nn.depth_to_space with Lambda layer since tf.nn is tensorflow operator, but Lambda encapsulates it as a keras layer. Same applies for "+" operator it is a tensorflow operator but Add()(...) is a keras layer so don't mix keras layers with tf operators.
Best.
I try to use Lambda layer and get another error.(same to tf.concat).
Do you train successfully by passing a `tfmot.quantization.keras.QuantizeConfig` instance to the `quantize_annotate_layer`?"Layer lambda:<class 'tensorflow.python.keras.layers.core.Lambda'> is not supported." You can quantize this layer by passing a `tfmot.quantization.keras.QuantizeConfig` instance to the `quantize_annotate_layer` API
Hello, my model can run normally in AI benchmark FP16 and FP32, but it fails in INT8. The error message is:
‘java.lang.illegalArgumentException:Cannot copy to a TensorFlowLite tensor (serving_default_input:0) with 2764800 bytes from a Java Buffer with 691200 bytes ’
What's the reason for this?
‘java.lang.illegalArgumentException:Cannot copy to a TensorFlowLite tensor (serving_default_input:0) with 2764800 bytes from a Java Buffer with 691200 bytes ’
What's the reason for this?
Hi,Hello, my model can run normally in AI benchmark FP16 and FP32, but it fails in INT8. The error message is:
‘java.lang.illegalArgumentException:Cannot copy to a TensorFlowLite tensor (serving_default_input:0) with 2764800 bytes from a Java Buffer with 691200 bytes ’
What's the reason for this?
you can refer to it here https://github.com/aiff22/MAI-2021-Workshop/blob/main/fsrcnn_quantization/fsrcnn.py
and uncomment line 64-65
deepernewbie
New member
Yes I could do thatThank you for your sharing~
I try to use Lambda layer and get another error.(same to tf.concat).
Do you train successfully by passing a `tfmot.quantization.keras.QuantizeConfig` instance to the `quantize_annotate_layer`?
from tensorflow_model_optimization.python.core.quantization.keras.default_8bit import default_8bit_quantize_configs
import tensorflow_model_optimization as tfmot
self.Depth2Space = kl.Lambda(lambda x: tf.nn.depth_to_space(x, 3))
x = tfmot.quantization.keras.quantize_annotate_layer(self.Depth2Space, quantize_config=default_8bit_quantize_configs.NoOpQuantizeConfig())(x)
Thank you very much!!!Yes I could do that
from tensorflow_model_optimization.python.core.quantization.keras.default_8bit import default_8bit_quantize_configs
import tensorflow_model_optimization as tfmot
self.Depth2Space = kl.Lambda(lambda x: tf.nn.depth_to_space(x, 3))
x = tfmot.quantization.keras.quantize_annotate_layer(self.Depth2Space, quantize_config=default_8bit_quantize_configs.NoOpQuantizeConfig())(x)
Hi, thank you for your advise and I can use quantization-aware training now~ I trained a small model with quantization-aware training now.Yes I could do that
from tensorflow_model_optimization.python.core.quantization.keras.default_8bit import default_8bit_quantize_configs
import tensorflow_model_optimization as tfmot
self.Depth2Space = kl.Lambda(lambda x: tf.nn.depth_to_space(x, 3))
x = tfmot.quantization.keras.quantize_annotate_layer(self.Depth2Space, quantize_config=default_8bit_quantize_configs.NoOpQuantizeConfig())(x)
(1) inference with tf model, the psnr is 29.33892
(2) inference with tflite int8, the psnr is 29.24394
I want to know is it reasonable. Thank you again~
Last edited:
deepernewbie
New member
As far as I know int8 conversion could result in slight decrease in accuracy so I think it is reasonableHi, thank you for your advise and I can use quantization-aware training now~ I trained a small model with quantization-aware training now.
(1) inference with tf model, the psnr is 29.33892
(2) inference with tflite int8, the psnr is 29.24394
I want to know is it reasonable. Thank you again~
The quantized model without the following two lines loses small psnr, but if I uncomment them, psnr decreases from 29dB to 20dB. I want to know whether it is normal?
I want to know is it reasonable. Thank you again~
Yes, model quantization always leads to accuracy loss (as you are cutting 32-bit weights to 8-bit). PSNR decrease from 29dB to 20dB is quite expectable if you are not using quantized aware training. With the latter option, the performance decrease should be much smaller, but it can still be up to 1-2dB depending on the exact model architecture.
I use my model in AI Benchmark the app is crash. And it run in test_tflite succesfully ,but per image run-time is 779s. I dont know why,I think may be the reason is size. I use keras-to-tflite to quantilize, when I was training model I write x=Input(None,None,3), when I was quantify I change the code to x= Input(360,640,3).Is it right operating?Or I use keras-to-tflite but actually the code is mix tf.nn.layer and tf.keras .Fuck tflite
Last edited:
deepernewbie
New member
while using tflite in PC the model is not using the GPU and falling back to CPU since the tflite interpreter is not optimized for Nvidia GPUs but for mobile GPUs but still 779s is a lot. it seems like your model is kind of "huge" for the challenge, Try a very simple model convert it to tflite and check it again.I use my model in AI Benchmark the app is crash. And it run in test_tflite succesfully ,but per image run-time is 779s. I dont know why,I think may be the reason is size. I use keras-to-tflite to quantilize, when I was training model I write x=Input(None,None,3), when I was quantify I change the code to x= Input(360,640,3).Is it right operating?Or I use keras-to-tflite but actually the code is mix tf.nn.layer and tf.keras .Fuck tflite
Regarding to app crash Andrey knows better but at least with the regular AI-Benchmark app from the store "depth_to_space" is not supported. You should join the beta program first and get the beta version of the app. If this layer is not the case it is another issue and Andrey might give you better explanation on this.
Last edited:
deepernewbie
New member
When are we going to get feedback for our recently sent models to the codalab server. It's been 1,5 days and still didn't get run result from the spreadsheet. This feedback is especially important since we dont have access to the hardware and not even know its architecture and drawbacks. Furthermore only 3 days left for the development phase, can this feedback loop be, at least for last 3 days, "near real-time"?
Thanks u so much .I try the model with the beta.But now it tell me the following, do you know why?while using tflite in PC the model is not using the GPU and falling back to CPU since the tflite interpreter is not optimized for Nvidia GPUs but for mobile GPUs but still 779s is a lot. it seems like your model is kind of "huge" for the challenge, Try a very simple model convert it to tflite and check it again.
Regarding to app crash Andrey knows better but at least with the regular AI-Benchmark app from the store "depth_to_space" is not supported. You should join the beta program first and get the beta version of the app. If this layer is not the case it is another issue and Andrey might give you better explanation on this.
[1XAW9.jpg")
Last edited by a moderator:
Hi, I think there is something wrong with the inference Time of my models.
The model in my submition '0311_submition_01.zip' should contains only a ResizeNearestNeighbor layer/
The model in my submition '0311_submition_02.zip' contains a lot of layers(e.g. conv, resize)
But they have the same inference time. Could you please help me check out what's going on?(May be this is still the runtime of the old model?Is there some requirements for naming the tflite models)
Thanks!

The model in my submition '0311_submition_01.zip' should contains only a ResizeNearestNeighbor layer/
The model in my submition '0311_submition_02.zip' contains a lot of layers(e.g. conv, resize)
But they have the same inference time. Could you please help me check out what's going on?(May be this is still the runtime of the old model?Is there some requirements for naming the tflite models)
Thanks!
[1XAW9.jpg")
deepernewbie
New member
make sure your have model.tflite in Downloads folder it seems like it could not find the fileView attachment 14What can I do
deepernewbie
New member
Maybe there are parallel cores which can infer in parallel and the general inference is bounded by the resize branch?Hi, I think there is something wrong with the inference Time of my models.
The model in my submition '0311_submition_01.zip' should contains only a ResizeNearestNeighbor layer/
The model in my submition '0311_submition_02.zip' contains a lot of layers(e.g. conv, resize)
But they have the same inference time. Could you please help me check out what's going on?(May be this is still the runtime of the old model?Is there some requirements for naming the tflite models)
Thanks!
View attachment 13
But thanks for sharing this
Last edited:
Hello! My model can run normally in AI benchmark, but after submitting, it is shown ‘Unable to run (unsupported operator type 127)’in the following link:
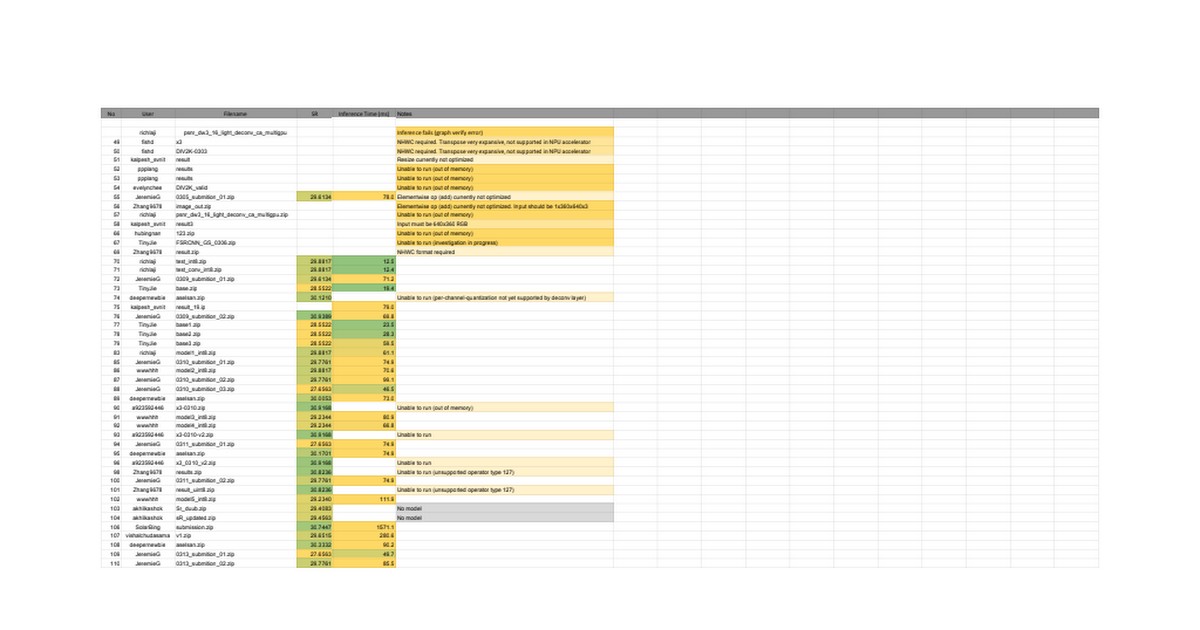
 docs.google.com
Why is this?
docs.google.com
Why is this?