Any technical questions and questions related to model conversion to TFLite format can be asked in this thread.
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Mobile AI Workshop Technical and Model Conversion Questions
- Thread starter Andrey Ignatov
- Start date
Dear organizers, I'm trying to convert my PyTorch model into a dynamic-input TFLite model, but the conversion fails when I set the input shape to be dynamic. Interestingly, the conversion works fine with a static input shape, and I can use the resulting TFLite model for inference speed evaluation.
Have you encountered similar issues before, or is there any recommended approach or workaround for this? Also, would it be acceptable to use a static-input TFLite model for quality evaluation instead? Thanks in advance!
Have you encountered similar issues before, or is there any recommended approach or workaround for this? Also, would it be acceptable to use a static-input TFLite model for quality evaluation instead? Thanks in advance!
Yes, there is indeed an issue with dynamic input size for PyTorch to TFLite conversion.
We will accept this for models converted from PyTorch. However, be prepared that we might ask you to provide the same model with additional input sizes if automatic tensor resizing won't work for your model.Also, would it be acceptable to use a static-input TFLite model for quality evaluation instead? Thanks in advance!
MAI-2025-Workshop/pytorch_to_tflite.py at main · aiff22/MAI-2025-Workshop
Contribute to aiff22/MAI-2025-Workshop development by creating an account on GitHub.
 github.com
github.com
Attachments

Does this error also occur during CPU-based inference?running in FP16+GPU Delegate mode
One possible issue might be the dimensionality of your tensor: GPU delegate might be expecting a 4D tensor, but it received a 3D one.GPU Delegate does not support BATCH MATMUL
If you are still unable to solve this problem, you can send us your model by email.I'm not sure what to do about it.
Thank you for your reply. The input size of the TFLite model I got from my conversion is fixed for the sRGB Enhancement Challenge [1,3,1024,1024]. I tried inference using CPU+FP16 and it worked even though it has slower inference time. However, I noticed that the Learn the Details/Evaluation of the sRGB Enhancement Challenge has a relevant note about the choice of mode: Testing Your Model on the Target Adreno / Mali Mobile GPUs section requires that I need to choose FP16+TFLite GPU Delegate when using the AI Benchmark. So this seems to indicate that this mode doesn't support enough arithmetic operations. If the target platform must use this mode, how do I address this technical issue to get higher inference speed? Or, if the target platform allows FP16+CPU mode, will all the teams' models be compared uniformly in this mode?Does this error also occur during CPU-based inference?
One possible issue might be the dimensionality of your tensor: GPU delegate might be expecting a 4D tensor, but it received a 3D one.
If you are still unable to solve this problem, you can send us your model by email.
By default, all solutions will be evaluated using FP16 + TFLite GPU Delegate mode. However, CPU backend will be used for solutions not supporting this option.Or, if the target platform allows FP16+CPU mode
TFLite GPU delegate is the easiest mode in terms of model adaptation as it supports nearly all common ops. However, yes, there might be some ops or layers requiring small adaptations. You've already been provided with a hint as for why BATCH MATMUL might be failing in your case.So this seems to indicate that this mode doesn't support enough arithmetic operations.
And, in principle, the general adaptation scenario looks as follows:
1. Identifying the op that is failing.
2. Removing this op from the model, converting it again, and checking that the issue is gone.
3. Trying one of the following options:
- Changing layer parameters, some non-default options are sometimes not implemented by the delegates
- Using or making an alternative PyTorch / TF layer implementation comprised of supported ops
- Replacing the layer with some other similar one
Thank you very much for your reply, I will consider your approach!By default, all solutions will be evaluated using FP16 + TFLite GPU Delegate mode. However, CPU backend will be used for solutions not supporting this option.
TFLite GPU delegate is the easiest mode in terms of model adaptation as it supports nearly all common ops. However, yes, there might be some ops or layers requiring small adaptations. You've already been provided with a hint as for why BATCH MATMUL might be failing in your case.
And, in principle, the general adaptation scenario looks as follows:
1. Identifying the op that is failing.
2. Removing this op from the model, converting it again, and checking that the issue is gone.
3. Trying one of the following options:
- Changing layer parameters, some non-default options are sometimes not implemented by the delegates
- Using or making an alternative PyTorch / TF layer implementation comprised of supported ops
- Replacing the layer with some other similar one
the format did not automatically switch from NCHW to NHWC
Are you using the ai_edge_torch plugin for model conversion like in this tutorial?
Dear organizers,Are you using the ai_edge_torch plugin for model conversion like in this tutorial?
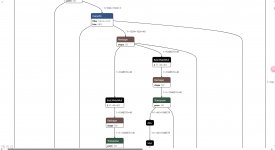
When testing our converted model on mobile, we encountered the error shown in the image. We're not sure what this error means. While checking the model, we suspect it might be related to the input channels. Could you please help us understand this error message?Thanks in advance for your support!

It's not an issue with the input channels - it's a problem with a bilinear resize layer. The issue is self-explanatory: half_pixel_center and align_corner options cannot be used at the same time. Try changing the parameters of the resize layer in your model.While checking the model, we suspect it might be related to the input channels.
Thank you very much for your guidance!It's not an issue with the input channels - it's a problem with a bilinear resize layer. The issue is self-explanatory: half_pixel_center and align_corner options cannot be used at the same time. Try changing the parameters of the resize layer in your model.
Dear organizers,Yes, there is indeed an issue with dynamic input size for PyTorch to TFLite conversion.
We will accept this for models converted from PyTorch. However, be prepared that we might ask you to provide the same model with additional input sizes if automatic tensor resizing won't work for your model.
It seems that TFLite models may not officially support dynamic input shapes.
Would it be possible for you to specify an additional fixed input size that we can use to evaluate the model quality?
Alternatively, we could implement this in the inference script by resizing the input images to a fixed size before passing them into the model, and then stretching the outputs back to the original dimensions after inference.
However, this approach may lead to a certain degree of accuracy loss.
Thank you for your understanding and support.
Best regards,
The correct one is:Could you please confirm whether my understanding is correct?
Because even after adding that line, my exported model still has a fixed input size.
Code:
dim_2 = 8 * torch.export.Dim("height", min=8, max=256)
dim_3 = 8 * torch.export.Dim("width", min=8, max=256)
edge_model = ai_edge_torch.convert(model.eval(), sample_input, dynamic_shapes=({2:dim_2, 3:dim_3},))However, this option is broken in the latest PyTorch releases. Therefore, we've allowed submission of TFLite models with a static size when they are converted from PyTorch.
Thank you very much for your guidance!The correct one is:
Code:dim_2 = 8 * torch.export.Dim("height", min=8, max=256) dim_3 = 8 * torch.export.Dim("width", min=8, max=256) edge_model = ai_edge_torch.convert(model.eval(), sample_input, dynamic_shapes=({2:dim_2, 3:dim_3},))
However, this option is broken in the latest PyTorch releases. Therefore, we've allowed submission of TFLite models with a static size when they are converted from PyTorch.
Hello, for Learned smart ISP challenge I need to download pretrained PUNET but could not find it.
Thanks for noticing. Instead of the PUNET model, we are now providing a more efficient MicroISP baseline. The corresponding link was added to the challenge description.
Dear organizers, I have a question regarding the "Mobile AI & AIM 2025 4K Quantized Image Super-Resolution Challenge"
After submitting these error logs occured
Traceback (most recent call last):
File "/tmp/codalab/tmpAqpyAb/run/program/evaluation.py", line 95, in <module>
raise Exception('Expected %d .png images'%len(ref_pngs))
Exception: Expected 100 .png images
— i've uploaded a zip file with 100 png images, but this error keep occuring
— do you have any suggestions for solving this problem?
After submitting these error logs occured
Traceback (most recent call last):
File "/tmp/codalab/tmpAqpyAb/run/program/evaluation.py", line 95, in <module>
raise Exception('Expected %d .png images'%len(ref_pngs))
Exception: Expected 100 .png images
— i've uploaded a zip file with 100 png images, but this error keep occuring
— do you have any suggestions for solving this problem?
Last edited:
Dear organizers, I have a question regarding the "Mobile AI & AIM 2025 4K Image Super-Resolution Challenge".
I used ai-edge-torch to convert a pytorch model to a TFLite model with fixed input dimensions. I encountered an issue when deploying my TFLite model to AI Benchmark.
It runs fine in CPU + FP16/32 and TFLite GPU Delegate + FP16/32 modes, but fails with errors under MediaTek Neuron, Android NNAPI, and Arm NN modes. Since this challenge will ultimately evaluate our TFLite model on the target MediaTek Dimensity 9400 platform, I’d like to know whether this means our model won’t run on the target platform, or whether the final evaluation will actually use the TFLite GPU Delegate as you said:
Thanks in advance!
I used ai-edge-torch to convert a pytorch model to a TFLite model with fixed input dimensions. I encountered an issue when deploying my TFLite model to AI Benchmark.
It runs fine in CPU + FP16/32 and TFLite GPU Delegate + FP16/32 modes, but fails with errors under MediaTek Neuron, Android NNAPI, and Arm NN modes. Since this challenge will ultimately evaluate our TFLite model on the target MediaTek Dimensity 9400 platform, I’d like to know whether this means our model won’t run on the target platform, or whether the final evaluation will actually use the TFLite GPU Delegate as you said:
By default, all solutions will be evaluated using FP16 + TFLite GPU Delegate mode. However, CPU backend will be used for solutions not supporting this option.
Thanks in advance!
or whether the final evaluation will actually use the TFLite GPU Delegate
Yes, all models not compatible with Dimensity's NPU would be evaluated on its GPU (using the TFLite GPU delegate).
yoonsuk kang
New member
Dear organizers, I have a question regarding the "Mobile AI & AIM 2025 Real Image Denoising Challenge"
Participants don't need to submit "model_none.tflite" filles, right?
Could you please confirm whether my understanding is correct?The correct one is:
Code:dim_2 = 8 * torch.export.Dim("height", min=8, max=256) dim_3 = 8 * torch.export.Dim("width", min=8, max=256) edge_model = ai_edge_torch.convert(model.eval(), sample_input, dynamic_shapes=({2:dim_2, 3:dim_3},))
However, this option is broken in the latest PyTorch releases. Therefore, we've allowed submission of TFLite models with a static size when they are converted from PyTorch.
Participants don't need to submit "model_none.tflite" filles, right?
Yes, if you are sending us model converted from PyTorch.articipants don't need to submit "model_none.tflite" filles, right?
In this challenge, we compute PSNR and SSIM scores on a CPU, so the result you are getting with the TFLite model on your local machine = your actual PSNR and SSIM scores.Without the image output, how can we test PSNR or SSIM on the output from the edge device?
nikolasent
New member
Dear Organizers,
I have a question regarding the AIM 2025 Real Image Denoising challenge.
Could you confirm, please, whether input and output data range for the model should be [0, 255] or [0, 1.0]? It is not obvious. The link to Matlab Scoring script returns 404 error so we cannot check it.
Another question is on axis order: the tutorial on pytorch model conversion suggests NCHW in the resulted tflite model, while the Data section on codalab suggests required shape is [1, 1088, 1920, 3], which is NHWC. Which one is correct?
Thank you in advance.
I have a question regarding the AIM 2025 Real Image Denoising challenge.
Could you confirm, please, whether input and output data range for the model should be [0, 255] or [0, 1.0]? It is not obvious. The link to Matlab Scoring script returns 404 error so we cannot check it.
Another question is on axis order: the tutorial on pytorch model conversion suggests NCHW in the resulted tflite model, while the Data section on codalab suggests required shape is [1, 1088, 1920, 3], which is NHWC. Which one is correct?
Thank you in advance.
Last edited:
Dear Organizers,
I have three questions regarding the AIM 2025 4K Image Super-Resolution Challenge.
The Get Data section on codalab suggests input shape is [1, 720, 1280, 3], which is NHWC. Does this mean it's a permute operation on the original RGB image ([1, 3, 720, 1280])?
You say articipants don't need to submit “model_none.tflite” filles, does this mean that only model.tflite needs to be submitted?
In the final test phase, no test data is provided, but my submission status shows failed: Expected 100 .png images but found 0 in the results directory. Can I ignore this error, and can you get the zip archive with this status failed?
Thank you!
I have three questions regarding the AIM 2025 4K Image Super-Resolution Challenge.
The Get Data section on codalab suggests input shape is [1, 720, 1280, 3], which is NHWC. Does this mean it's a permute operation on the original RGB image ([1, 3, 720, 1280])?
You say articipants don't need to submit “model_none.tflite” filles, does this mean that only model.tflite needs to be submitted?
In the final test phase, no test data is provided, but my submission status shows failed: Expected 100 .png images but found 0 in the results directory. Can I ignore this error, and can you get the zip archive with this status failed?
Thank you!
[0, 255]Could you confirm, please, whether input and output data range for the model should be [0, 255] or [0, 1.0]?
Another question is on axis order: the tutorial on pytorch model conversion suggests NCHW in the resulted tflite model, while the Data section on codalab suggests required shape is [1, 1088, 1920, 3], which is NHWC. Which one is correct?
By default, we are using NHWC format. You can get a TFLite model with NHWC input format by using the following conversion option:The Get Data section on codalab suggests input shape is [1, 720, 1280, 3], which is NHWC. Does this mean it's a permute operation on the original RGB image ([1, 3, 720, 1280])?
Code:
sample_input = (torch.randn(1, heights, width, 3),)
model = ai_edge_torch.to_channel_last_io(model, args=[0], outputs=[0])
edge_model = ai_edge_torch.convert(model.eval(), sample_input)Yes.You say articipants don't need to submit “model_none.tflite” filles, does this mean that only model.tflite needs to be submitted?
Yes.xpected 100 .png images but found 0 in the results directory. Can I ignore this error, and can you get the zip archive with this status failed?