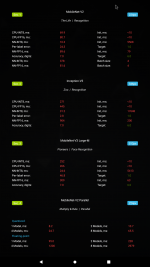
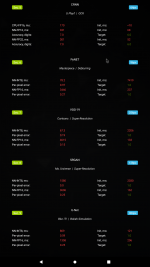
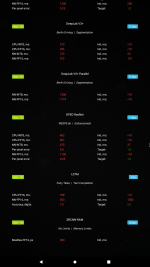
I have a vim3 which includes an amlogic A311D chip.
This chip has a npu built in but it does not seem to have been used when benchmarked currently, as the ai benchmark is the same as on the s922x chip which does not have an npu.
What is required to be able to use the npu when running this benchmark?
What would you imagine might be missing for the npu to be used?
This chip has a npu built in but it does not seem to have been used when benchmarked currently, as the ai benchmark is the same as on the s922x chip which does not have an npu.
What is required to be able to use the npu when running this benchmark?
What would you imagine might be missing for the npu to be used?